2.3.16
Results of the 2015 Underhanded C Contest
We have judged all submissions, and are pleased to announce the runners up and winner of the 2015 Underhanded C Contest. This year we had over 40 submissions, and they were all of high quality. As a result, our list of runners up is pretty long. I will provide anchor links below if you want to skip ahead
This year's challenge (detailed below) is a real-world problem in nuclear verification, sponsored by and designed in partnership with the Nuclear Threat Initiative (http://www.nti.org/), a nonprofit, nonpartisan organization working to reduce the threat of nuclear, chemical and biological weapons. We hope that this emphasizes the need for care and rigor, not to mention new research, in secure software development for such applications.
Finally, we are going to run a live Reddit AMA ("Ask Me Anything," for those of you who, like me, still use a tape recorder and a Commodore PET CBM) next Tuesday, February 9th, at 1:00pm. We'll post more specifics later, but if you have questions about Underhanded C, the contest or the problem, this will be a great opportunity to ask.
- Review of challenge problem (older post)
- Nan bug submissions
- A note on realism
- Runners up
- The winner
An overview of NaN poisoning attacks
Many of the submissions (about a third of them!) used the same trick, one that every programmer should be aware of. A floating-point variable can be set to NaN ("not a number") as a result of certain computations with undefined results -- for example, computing sqrt(-1.0) or 0/0. NaN values have the following properties:
- A computation involving a NaN input will often have a NaN result;
- A comparison with a NaN will evaluate to false.
That second fact is a syntactic limitation of many programming languages: only some datatypes can hold an undefined value. Mathematically speaking, if x is undefined, then we should expect
y = ((int) x) or y = (x >= 5)Anyways, this suggests a NaN poisoning trick:
- Find a way to introduce a NaN if some weird input is given to the program;
- Allow the NaN to propagate through to the final comparison statistic;
- Compare it to a threshold so that a false comparison (and hence NaN value) returns true, using a line such as:
return (detection_score < threshold ? 0 : 1);
So how clever is this? It depends on how you introduce the NaN. Some entries just assumed that the host country could smuggle one into the input, which we did not consider a feasible attack. Some entries computed test statistics that required a division or a square root or a logarithm, so that an unusual input would yield a NaN result. Here is a good example submitted by Peter Eastman:
int match(double* test, double* reference, int bins, double threshold) {
double* testMinusBaseline = (double*) malloc(bins*sizeof(double));
double* referenceMinusBaseline = (double*) malloc(bins*sizeof(double));
for (int i = 0; i < bins; i++) {
testMinusBaseline[i] = fmax(0.0, test[i]-baseline[i]);
referenceMinusBaseline[i] = fmax(0.0, reference[i]-baseline[i]);
}
[etc etc etc]
// Compute the Pearson correlation of test with reference.
double correlation = 0.0;
for (int i = 0; i < bins; i++)
correlation += (testMinusBaseline[i]-meanTest)
*(referenceMinusBaseline[i]-meanReference);
correlation /= stddevTest*stddevReference;
return (correlation < threshold ? 0 : 1);
}
The code to subtract off the baseline[] array clamps all negative values to zero, so that if a test warhead could somehow be engineered so that test[i]<=baseline[i], then the correlation comes out as 0/0 == NaN.
One problem with NaN poisoning is that many coders are cautious about dividing by zero; to a C programmer, looking at a floating-point division without a zero-check is a bit like watching a toddler playing with a steak knife. Such oversights are likely to draw attention on review. Some submitters addressed this by introducing zero-checks that didn't work, to wit this entry by Michael Dunphy:
/* dot: dot product between x and y */
static inline double dot(double *x, double *y, int n, unsigned int err) {
double dp = 0;
for (int i = 0; i < n; i++) dp += x[i]*y[i];
volatile double tmp = dp; // check for zero, NaN or +/- infinity
if ( (dp == 0) || (tmp != dp) || ((tmp == dp) && (tmp - dp) != 0) ) err = 1;
return dp;
}
/* match: compute cosine similarity and return 1 if >=threshold, else return 0 */
int match(double *test, double *reference, int bins, double threshold) {
unsigned int err = 0;
double magr = sqrt(dot(reference, reference, bins, err));
double magt = sqrt(dot(test, test, bins, err));
double r = dot(test, reference, bins, err) / (magt*magr); // cosine similarity
if ( err > 0 ) return 0; // test fails for any invalid data
return r >= threshold ? 1 : 0; // check r against threshold for match result
}
This sets an error flag if anything would trigger a NaN, but the err flag is supposed to be passed by reference and is missing an '&' in the declaration.
A few other interesting NaN tricks included a fun entry by Sean Egan, which combined a straightforward match() function with the following main() code to parse test[] and reference[] values from a text file input:
double *test = malloc(bins * sizeof(double));
double *ref = malloc(bins * sizeof(double))
memset(test, -1, bins * sizeof(double));
memset(ref, -1, bins * sizeof(double));
/* Parse the remaining arguments into the arrays. */
for (i = 0; i < bins; i++) {
sscanf(argv[i + 2], "%lf", &ref[i]);
sscanf(argv[bins + i + 2], "%lf", &test[i]);
}
int res = match(test, ref, bins, threshold);
The arrays are memset() to 0xFF, and then loaded with numbers from the file. If the file contains an entry that is not parseable as a number, which can happen by a lot of tricks such as funny Unicode characters that resemble digits, sscanf() will leave that array element unassigned, and a double variable made out of 0xFF values is a NaN.
Generally, NaN poisoning attacks did not make our short list, either because (1) they assumed a host country could tinker with the input, (2) they were too brazen in performing a floating point operation without a check, or (3) they arranged for a NaN to occur by conditions that were too contrived. There were a couple, though, that got our attention, that we list below.
A Note On Realism
A winning entry needs to allow a false positive that can be achieved under realistic circumstances, and which rarely ever happens by accident. We noted that the submissions fell into several categories in this department:
- Some entries just made simplistic or unrealistic assumptions about what the host country could do, for example corrupting an input array.
- Some entries engineered a bug that would occur when a certain kind of test spectrum is introduced, such as one without spikes or one with an extreme value. These we call data-triggered attacks.
- Some entries engineered a bug triggered by some environmental factor in the computer -- such as setting the uid on a file or tampering with the system clock. These we call environment-triggered attacks.
Environment-triggered attacks require that a host country can cause some other effect in the computer, that may seem to bear little relevance to the program. Depending on the trigger, this could be achieved by tinkering with the OS, or breaking a physical connection somewhere. Two submissions from Sarah Newman and S. Gilles, for example, parallelized their match() function and triggered underhanded behavior if someone changes the number of available CPUs during the computation.
Are environment-triggered attacks realistic?
Would a host country in a nuclear inspection scenario be allowed to tamper with
a computer, for example to futz with the system clock or number of CPUs?
First of all, environmental tampering can be so subtle that it isn't really
a matter of whether someone will
On the other hand, some submissions featured data-triggered attacks that caused by conditions which are not realistic, such as presenting a spectrum so energetic that one of the bins exceeds MAX_INT. We did not dictate any specific rules about the values of the input array, beyond encouraging the reader to Google gamma ray spectra; however, we did give far more points to entries that could be triggered by subtle means, which tend to correspond to physically realizeable conditions.
All told, we do tend to like data-triggered attacks because they don't rely upon any extra assumptions, and give us a self-contained attack.
Runners Up
Philipp Klenze
This is a NaN poisoning bug, using a likelihood ratio test:
long double factorial(int n)
{
return (n<2)?1:n*factorial(n-1);
}
// returns poisson probability mass function
double poisson(int k, double lambda)
{
return powl(lambda, k)*expl(-lambda)/factorial(k);
}
//returns the likelihood ratio
double logLikelihoodRatio(int k1, int k2)
{
double mean=(k1+k2)/2.0;
return -2*(log(poisson(k1, mean))
+ log(poisson(k2, mean))
- log(poisson(k1, k1))
- log(poisson(k2, k2)));
}
double logLikelihoodRatioSum(double * test, double * reference, int bins)
{
double llq=0;
int i;
for (i=0; i<bins; i++)
{
llq+=logLikelihoodRatio(test[i], reference[i]);
}
return llq;
}
The match() function compares logLikelihoodRatioSum to a threshold.
This is interesting because it doesn't simply strike a NaN by computing 0/0; the NaN comes from computing a bin value's probability under a Poisson distribution, which occurs for bin values approaching 2000. This is not only a realistic way to compare two arrays of event counts, but it allows a bug to be realistically triggered. To quote Mr. Klenze:
To make use of this bug, the cheating country will have to assure that a bin has a count of at least 1686. I would recommend an expected peak value of 1860, which will almost always guarantee this (assuming a Poisson distribution, again). This can be archived by packing the fake full of a short-lived nuclide with a single strong peak, or alternatively setting up an x-ray device inside the fake.
This is a very intelligent way to achieve an extreme value bug. Bugs of this kind usually require absurdly high input values to trigger overflow or underflow in arithmetic, which does not admit a physically realizable attack; but by computing a probability for a likelihood ratio, it's easy to hit those absurd values with common pdfs, realistic parameters, and a smallish input value.
Ghislain Lemaur
This entry hides a NaN bug in logging code.
double SSDWR(double * e, double * o){
double sum = 0;
for(int i=0; i<glob.bins; ++i){
sum += pow( o[i]-e[i], glob.diff_exp) / e[i];
}
return sum;
}
int statistic_test(double chi2){
return chi2 > glob.threshold;
}
int match(double * test, double * reference, int bins, double threshold){
glob.bins = bins;
glob.threshold = threshold;
glob.diff_exp = 2.0;
LogInit();
LogStr("Test params: ");
LogStr("exp="); LogFloat(glob.diff_exp);
LogStr("threshold="); LogFloat(glob.threshold);
int ret = !statistic_test(SSDWR(reference, test));
LogStr("result="); LogStr(ret ? "yes" : "no"); LogStr("\n");
LogFlush();
return ret;
}
Lots of logging. What's going on here? Here's the LogStr function (LOG_SIZE is the length of the glob.long_str array):
void LogStr(char* s){
if(LOG_SIZE < snprintf(NULL, 0, "%s %s", glob.log_str, s)){
if(ENABLE_LOG) fprintf(glob.log_file ? glob.log_file :
stdout, "%s ", glob.log_str);
strncpy(glob.log_str, s, LOG_SIZE);
}
else
sprintf(glob.log_str, "%s %s", glob.log_str, s);
}
So this tries to append a message onto the log if it fits. There is an extra space between the top snprintf and the bottom snprintf, and LOG_SIZE doesn't account for the extra byte needed for a null terminator, so a log message of just the right length will write two bytes past the log string -- into the variable glob.diff_exp, used to store the exponent 2.0.
Because of little-endian representation, overwriting the first two bytes of the exponent changes it to a value that is just a tiny bit more than 2.0 -- subtle enough that it will still display as 2.0 when the logging code prints it out! But since it is not an integer, pow( o[i]-e[i], glob.diff_exp) returns NaN whenever the first argument is negative.
Very well, but what event triggers this log overflow that triggers the NaN?
void LogInit(){
char filename[]="/tmp/log.txt";
glob.log_str[0] = 0;
glob.log_file = ENABLE_LOG==1 ? fopen(filename,"a") : NULL;
if(glob.log_file==NULL){
struct stat s;
if(0==stat(filename, &s))
sprintf(glob.log_str, "Unable to open %s: owned by %d\n",
filename, s.st_uid);
else
sprintf(glob.log_str, "Unable to open %s\n", filename);
}
}
A host country sets the uid of /tmp/log.txt to a five-digit number. Tinkering with the uid of a log file causes the program to misbehave.
Josh Lospinoso
This is a straightforward typo:
int match(double *test, double *reference, int bins, double threshold) {
int bin=0;
double testLength=0, referenceLength=0, innerProduct=0, similarity;
for (bin = 0; bin < bins; bin++) {
innerProduct += test[bin]*reference[bin];
testLength += test[bin]*test[bin];
referenceLength += reference[bin]*reference[bin];
}
if (isinf(innerProduct)||isinf(testLength)||isinf(referenceLength)) {
return isinf(testLength)&&sinf(referenceLength) ? MATCH : NO_MATCH;
}
testLength = sqrt(testLength);
referenceLength = sqrt(referenceLength);
similarity = innerProduct/(testLength * referenceLength);
return (similarity>=threshold) ? MATCH : NO_MATCH;
}
This is cosine similarity (normalized correlation) that appears to check for infinite values. It will return NO_MATCH if one of the values is infinite, unless both test and reference are infinite (why?) The bug is a missing 'i' from an isinf() call, that instead returns the sine of referenceLength--a value that is unlikely to be 0, and thus likely to be true.
To "trigger" this, you need a test array with an extreme value that would make the test vector of infinite length, i.e. present data that causes an overflow. This is not likely to be realistically achievable as a data-triggered attack.
Stephen Dolan
This one computes the Euclidean distance between the test[] and reference[] arrays, with an extra quirk of removing the largest outlier distance from the sum. I don't quote it here, but this also includes validation code to flag infinite values.
int match(double * test, double * reference, int bins, double threshold)
{
double sum_dist_sq = 0, outlier = 0;
int i;
/* Validate the test data before doing any computations.
If it fails, return a failed match. */
if (!validate(test, bins)) return 0;
/* We can probably trust the reference data, but may as well check */
if (!validate(reference, bins)) return 0;
/* Find the L2 norm and the biggest outlier in one pass.
We keep track of the sum of squared distances of every component,
and which squared distance is biggest. After the loop, we remove
the biggest outlier. */
for (i = 0; i < bins; i++) {
double dist_sq = (test[i] - reference[i]) * (test[i] - reference[i]);
sum_dist_sq += dist_sq;
if (dist_sq > outlier) outlier = dist_sq;
}
/* Remove the largest outlier */
sum_dist_sq -= outlier;
return sqrt(sum_dist_sq) < threshold;
}
The bug is due to a property of floating-point arithmetic: if a floating-point value X is large enough, X+1 is the same as X, due to the limited precision of the representation. If the first value of (test[i]-reference[i]) is much, much larger than the others, like 10E8 times as large, then all the subsequent values will have no effect when their squares are added to the "sum". This causes the sum to be equal to that first extreme value, which is also the outlier that is subtracted from the sum--yielding zero.
This is triggered by presenting a test[] array whose first value is unrealistically large relative to the others.
Matt Bierner
This one was very complex and ultimately suspicious, but fun.
/**
"觬巂 - "
Translation: "Error - "
Localized error label for the Glorious Democratic Peoples Republic Of Bob.
*/
#define ERROR_LABEL "\x89\xec\x5d\xc2\0\0 - "
static void* error_message = ERROR_LABEL "A math error occured. Returning that no match was found.";
void error_messager() {
printf("%s", error_message);
}
So, some contrived error-handling code with a Unicode alphabet from the Republic of Bob.
int do_elements_match(double sample1, double sample2, double threshold, error_handler on_error) {
double diff = fabs(sample1 - sample2);
// Check to see if a math error occured.
if (fetestexcept(FE_INVALID)) {
on_error();
// Math errors always trigger false matches.
return 0;
}
return diff <= threshold;
}
int match(double* test, double* reference, int bins, double threshold) {
for (unsigned i = 0; i < bins; ++i)
if (!do_elements_match(test[i], reference[i], threshold, error_message))
return 0;
return 1;
}
This match() function calls a separate function, with an error handler to alert the user and properly return 0 if there is any floating point exception raised.
The bug is that the error handler is called error_messager, and the code instead passes error_message, which is a string. The code mistakenly calls a string as a function, which would normally cause crashy things to happen--except the initial bytes of the Unicode string are valid x86 instructions, that pop a stack frame and causes do_elements_match to return true.
To trigger this, one needs to initially perform some operation that computes an invalid floating point value, for example finding an excuse to compute a sqrt(-1) before the match() function is called. Why and how is left unspecified, but this is a kind of environmental trigger. It is not clear how this would be triggered externally only under the right conditions engineered by the host country.
Gregory Stewart
This entry played some tricks with data structures and gotos, to create a program that misbehaves if the program performs match() multiple times:
int match(double *test, double *reference, int bins, double threshold)
{
struct sample *s, *prev, *head;
int i, result;
s = prev = head = NULL;
for (i = 0; i < bins; i++) {
s = sample_create(test[i], reference[i], threshold);
if (prev)
prev->next = s;
else
head = s;
prev = s;
}
result = sample_match(head);
sample_destroy(&s);
return result;
}
int sample_match(struct sample *s)
{
int result;
result = 1;
if (!s)
goto error;
while (s) {
if (fabs(s->test - s->reference) > s->threshold)
goto error;
s = s->next;
}
goto done;
error:
result = 0;
done:
return result;
}
struct sample *
sample_create(double test, double reference, double threshold)
{
struct sample *s;
if (pool_acquire(&s)) {
s->test = test;
s->reference = reference;
s->threshold = threshold;
s->next = NULL;
}
return s;
}
The input arrays are loaded into a linked data structure of sample nodes, which is then passed over in order to match them. Nodes are acquired from an allocated pool, and returned to the pool after the match (sample_destroy).
The underhanded part is a bug that causes a memory leak --the call to sample_destroy(), above, only "destroys" the last node in the list--and pool_acquire misbehaves as soon as the pool is empty and it has to malloc() a new node:
int pool_acquire(struct sample **s)
{
struct sample *p;
int result;
result = 1;
if (!s) goto error;
p = pool_head;
if (!p) {
p = malloc(sizeof(struct sample));
if (!p)
goto error;
memset(p, 0, sizeof(struct sample));
*s = p;
} else {
if (p->next) {
pool_head = p->next;
p->next = NULL;
} else {
pool_head = NULL;
}
*s = p;
goto done;
}
error:
result = 0;
done:
return result;
}
This bug is perceptual in nature: several functions in this code follow a goto pattern of
goto done;
error: result = 0;
done: return result;
Because one node is always returned to to the allocation pool at the end of match(), the allocation pool has at least one entry at the start of match(). So:
- Until the pool runs out, the behavior of match() is normal.
- Once the pool runs out, the output of match() depends entirely on the first element of test[] and reference[]. If they are close, the output is a match.
All told, however, it is somewhat suspicious to copy an array over into a linked data structure, especially if the underlying comparison algorithm would be a very simple loop.
Stephen Oman
This is a straightforward but very clever negative-number bug. The code computes the area of peaks in the spectra and compares them, but a bug causes the test[] array values to be negated. Nobody expects the spectrum values to be negative, or expects that the area under a peak would therefore be negative. This causes the following code to always pass:
lb_match = (lb_rpeak/tpeak) <= (1.0 + DBL_EPSILON) ? 1 : 0;
ub_match = (tpeak/ub_rpeak) <= (1.0 + DBL_EPSILON) ? 1 : 0;
Here, tpeak is the area under a peak. Since it is a negative number, the ratio on the left is always below the threshold. How does the data end up mistakenly negated? Like so:
if(!feof(file_ptr)) {
int s_seconds, e_seconds, t_seconds = 0; // start, end and total
fscanf(file_ptr, "%d",&s_seconds);
fscanf(file_ptr, "%d", &e_seconds);
t_seconds = e_seconds - s_seconds;
if(t_seconds != 0) {
double *current = data;
for(int i=0; i<bins; i++) {
if(feof(file_ptr)) {
printf("get_data: not enough bins in file %s\n", filename);
printf("expected %d, read %d before EOF\n", bins, i);
return 5;
}
fscanf(file_ptr, "%lf", current);
*current = (*current)/(double)t_seconds;
current++;
}
} else {
printf("get_data: unable to normalise data, time is 0\n");
return 6;
}
}
A main function expects a spectrum with two extra numbers showing the starting and ending time of a scan. It then normalizes the spectrum from counts to counts/sec, by computing the time differential and dividing by it (in the bolded lines of the code above).
Here, if a host country can somehow mess with the clock that provides that starting and ending time, it can trip the clock during the scan so that the ending time comes before the starting time. This produces a negative time differential that is multiplied (divided, really) into every array element.
This is an environmental attack: rather than triggering the bug by placing the right kind of unusual test object in front of the scanner, the host country triggers the bug through some aspect of the computing environment running the program, in this case the system clock.
And now the winner:
The Winner
The Winner
Linus Åkesson
Mr. Åkesson actually provided a detailed write-up of his entry, in two parts here and here.
On paper, this entry first tests the total energy in the test spectrum to make sure it isn't empty or conspicuously small. Then it filters and smooths the spectra in order to highlight their peaks, and compares them by normalized correlation.
The entry starts with the following lines in a header file:
#define N_SMOOTH 16 /* Size of smoothing kernel */
typedef double float_t; /* Desired precision for floating-point vectors */
int match(float_t *test, float_t *reference, int bins, double threshold);
double spectral_contrast(float_t *a, float_t *b, int length);
This header file defines float_t as double precision, although by default math.h defines float_t as single precision. One C file #includes this header file, and one C file (where spectral_contrast is defined) #includes math.h. Neither file #includes both, so there is no overridden typedef of float_t. As a result, match takes an array of 8-byte double-precision floating point numbers, and hands them to a function that expects an array of 4-byte single-precision floating point numbers.
Beyond that type confusion, the code does nothing unusual or suspicious or quirky or different: it is a bog-standard implementation of preprocessing followed by normalized correlation. There is really nothing underhanded in the rest of the code! Here is the comparison code (which is called after the program verifies that the spectrum has sufficient energy, so there is no division by zero error):
#include <math.h> /* sqrt */
static double dot_product(float_t *a, float_t *b, int length) {
double sum = 0;
int i;
for(i = 0; i < length; i++) sum += a[i] * b[i];
return sum;
}
static void normalize(float_t *v, int length) {
double magnitude = sqrt(dot_product(v, v, length));
int i;
for(i = 0; i < length; i++) v[i] /= magnitude;
}
double spectral_contrast(float_t *a, float_t *b, int length) {
normalize(a, length);
normalize(b, length);
return dot_product(a, b, length);
}
So what goes wrong? The function expecting 4-byte numbers will essentially see every 8-byte double as two variables. This has two effects:
- It causes the function to only scan over the first half of the array, interpreting the first 4*length bytes as
lengthnumbers; - The bits of each 8-byte double ends up interpreted as two numbers in a weird way.
How? 4- and 8-byte numbers have different exponent lengths, so if we mistakenly view an 8-byte number as two 4-byte numbers, some exponent bits will be mistaken for mantissa bits, and the second number will be made entirely out of mantissa bits from the 8-byte number.
Mr. Åkesson observed that the spectra we are testing consist of whole-number counts, however, and the mantissa of an IEEE floating-point number is left-justified; so as long as those counts are less than a million (less than 20 bits,) all the "content" of the 8-byte number is on the left side, and the rest will be zeroes. Thus the second half of the double will be mistaken for a 4-byte value 0.0.
Meanwhile, the left side will be confused for a 4-byte value with the same sign, a smaller exponent, and with some zero bits of the exponent passed along to the mantissa. This is a nonlinear distortion that turns an integer into a real number with a highly squashed range (as shown in the figure below, taken from Mr. Åkesson's summary.)
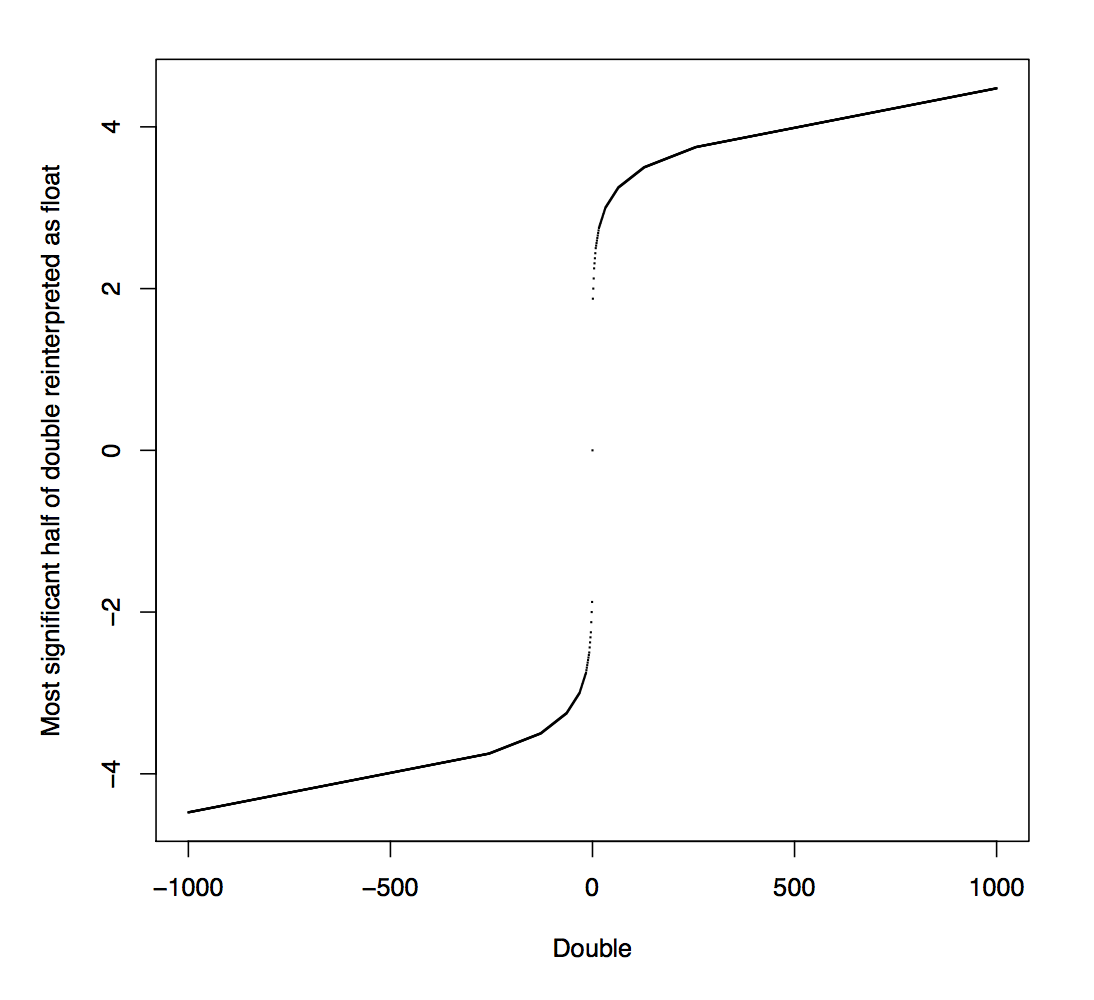
We'll get to the squashing in a minute, but just to hammer this home: due to the confusion about the float_t type, an input array of double values that looks like
...will be misinterpreted as< ... a, b, c, d, e, f, g, h ... >
...where SQUASH is the function plotted above. Both test[] and reference[] are misinterpreted in this way; the zeroes don't have any effect on the correlation between the two vectors, and we can ignore them.< ... SQUASH(a), 0, SQUASH(b), 0, SQUASH(c), 0, SQUASH(d), 0 ... >
Now for the SQUASHing: you will observe that SQUASH(10) and SQUASH(1000) are not very far apart. Imagine you remove most, but not all, of the fissile material from a test object. The effect on the array as seen by the spectral_contrast() function won't be very much, owing to this flattening effect.
Using this, a host country's recipe for beating the system is leaving behind a small amount of fissile material, so there is a tiny bit of energy, and then placing something else in the test object that produces a substantial spectral signature in the right half of the spectrum. This energy in the right half allows the spectrum to pass the initial test for total energy, after which the right half of the spectrum is ignored. Then, the SQUASH effect results in a test[] and reference[] array that aren't that different from one another, even though there are very different amounts of fissile material and very different magnitudes in the original spectrum.
Why did we like this one?
- The attack is realistically achievable without triggering some effect in the computer, like tampering with a system clock or a file permission;
- It uses a real-world approach to comparing spectra, rather than something simple or contrived;
- If you miss the type confusion, there is nothing at all about the remaining code that looks the slightest bit suspicious or unusual;
- It gets down to the bitwise representation of floating-point numbers, and causing a confusion of datatypes with usable results is ingenious;
- It exploits the fact that the doubles hold whole number counts, which allows the miscasting of doubles to work;
- The attack is actually transparent to all the filtering and preprocessing, which preserves the whole-number property of the data;
- Despite all this, it's still only 60-odd lines of code, that looks incredibly innocent.